
티스토리 뷰

GPT 모델이란?
GPT는 "Generative Pre-trained Transformer"의 약어로, OpenAI에서 개발한 언어 모델입니다. GPT 모델은 대규모 텍스트 데이터에서 미리 학습된 이후, 새로운 텍스트를 생성하거나 다양한 자연어 처리(NLP) 태스크를 수행할 수 있습니다.
Transformer 아키텍처
GPT 모델은 Transformer 아키텍처를 기반으로 합니다. Transformer는 2017년 Vaswani et al.에 의해 소개된 딥러닝 모델로, 순차 데이터(예: 자연어 텍스트)를 처리하기 위해 설계되었습니다. Transformer 아키텍처는 self-attention 매커니즘을 사용하여 입력 시퀀스의 다른 부분들의 중요도를 가중합하여 예측하는 방식으로 작동합니다.
미세 조정(fine-tuning)
GPT 모델은 대규모 텍스트 데이터에서 미리 학습된 이후, 특정 자연어 처리 태스크를 위해 미세 조정(fine-tuning)됩니다. 이를 위해서는 해당 태스크의 작업에 맞는 학습 데이터를 제공해야 합니다. 미세 조정은 GPT 모델이 특정 자연어 처리 태스크를 수행할 수 있도록 모델의 매개변수를 조정하는 과정입니다.
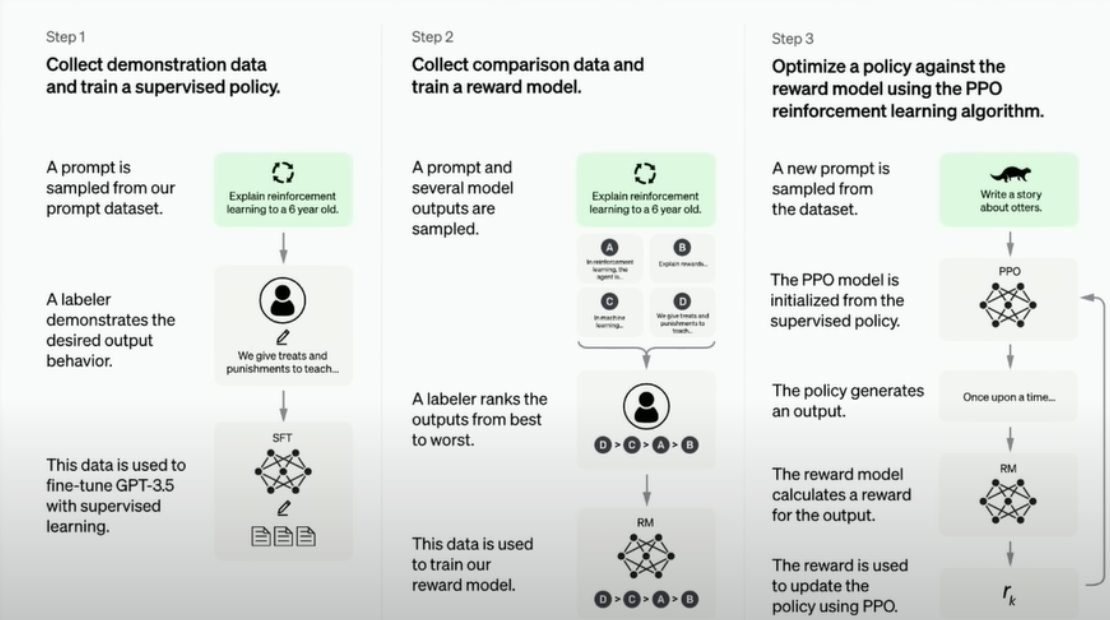
GPT 모델의 활용 예시
GPT 모델은 다양한 자연어 처리 태스크에서 활용될 수 있습니다. 몇 가지 예시를 살펴보면:
- 챗봇(Chatbot) : GPT 모델은 챗봇의 응답 생성을 위해 활용될 수 있습니다.
- 언어 번역(Language Translation) : GPT 모델은 다국어 언어 번역 태스크를 수행할 수 있습니다.
- 질문 답변(Question Answering) : GPT 모델은 지문에서 질문에 대한 답변을 생성하는 태스크를 수행할 수 있습니다.
- 자연어 이해(Natural Language Understanding) : GPT 모델은 텍스트 분류(Text Classification)나 감성 분석(Sentiment Analysis) 등 다양한 자연어 이해 태스크에서 활용될 수 있습니다.
GPT 모델의 장단점
GPT 모델은 대규모 텍스트 데이터를 기반으로 미리 학습되어 있기 때문에, 새로운 자연어 처리 태스크를 위해 미세 조정(fine-tuning)만으로도 높은 성능을 발휘할 수 있습니다. 또한, GPT 모델은 Transformer 아키텍처를 기반으로 하기 때문에, 임의의 위치에 있는 입력 토큰들 사이의 의존성을 쉽게 파악할 수 있습니다.
하지만 GPT 모델은 다음과 같은 단점도 가지고 있습니다.
대규모 텍스트 데이터를 기반으로 미리 학습되기 때문에, 학습 데이터에 없는 단어나 문장 패턴에 대해서는 성능이 떨어질 수 있습니다.
GPT 모델은 매우 복잡한 모델이기 때문에, 학습에 많은 컴퓨팅 리소스와 시간이 필요합니다.
GPT 모델의 발전
GPT 모델은 2018년 GPT-1 모델을 출시한 이후, GPT-2, GPT-3 등의 모델이 개발되었습니다. 특히, GPT-3는 이전 모델들과는 다르게 대규모 텍스트 데이터 학습과 더불어, 더 많은 파라미터와 연산 리소스를 가지고 있어, 이전 모델들보다 더 높은 성능을 보여주고 있습니다.
결론
GPT 모델은 대규모 텍스트 데이터 기반으로 미리 학습된 언어 모델로, 다양한 자연어 처리 태스크에서 활용될 수 있습니다. GPT 모델은 미세 조정(fine-tuning)을 통해 특정 자연어 처리 태스크에 맞게 조정될 수 있습니다. GPT 모델은 다양한 장점과 함께 몇 가지 단점도 가지고 있으며, 이를 극복하기 위해 더 발전하고 있습니다.
'IT Story > ChartGPT' 카테고리의 다른 글
| 비전공자 주목! 단 몇 분 만에 챗GPT(ChatGPT) 프롬프트 마스터하기 (0) | 2024.03.08 |
|---|---|
| GPT-3.5 Architecture and Chart GPT: A Powerful Combination for Data Analysis and Business Insights (1) | 2023.03.15 |
| Chat GPT (챗GPT) 알아보기 (0) | 2023.03.03 |
- Total
- Today
- Yesterday
- AWS
- frontend
- Docker 관리
- AI
- Redis
- MongoDB
- GPT
- svelte
- 쉽게따라하기
- nestjs
- 한식
- typescript
- lambda
- 실습
- ChartGPT
- 딥러닝
- 따라해보기
- cloudcomputing
- 따라하기
- ML
- Containerization
- EC2
- 티스토리
- python
- DevOps
- docker
- 개발이야기
- ubuntu
- 클라우드
- svelte 따라해보기
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |